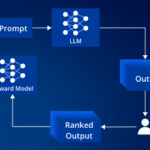
Reinforcement Learning from Human Feedback (RLHF) is no longer just a research trick — it’s the practical way teams align large language models to be helpful, safe, and on-brand. But the algorithm (reward model + policy tuning) is only half the work. To operate RLHF at SaaS scale you need robust human-feedback pipelines: consistent rating […]