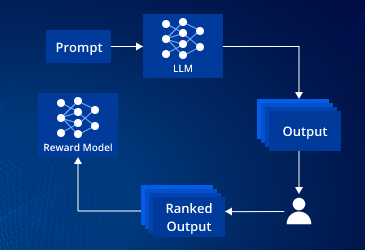
Reinforcement Learning from Human Feedback (RLHF) is no longer just a research trick — it’s the practical way teams align large language models to be helpful, safe, and on-brand. But the algorithm (reward model + policy tuning) is only half the work. To operate RLHF at SaaS scale you need robust human-feedback pipelines: consistent rating interfaces, label quality controls, continuous integration (CI) for alignment, cost-aware sampling, and production monitoring that connects model drift back into your rater queue.
This guide walks through the end-to-end operational blueprint for RLHF ops: design, tooling, data flows, rater ops, reward-model training, model-deployment patterns, and governance. It’s written for product, ML, and ops teams who need to ship aligned models reliably and repeatably.
The operational thesis
-
Treat RLHF as software + people engineering: your primary investments are in data pipelines, rater ops, and CI, not just RL algorithms.
-
Start with a clear feedback taxonomy that maps to product outcomes (helpfulness, accuracy, tone, safety).
-
Build a rater workflow that combines short, high-signal tasks, tooling for consistency, and automated QA (inter-rater reliability, calibration).
-
Automate reward-model and SFT training in CI, with gating checks (quality, regressions, safety) before PPO or production deployment.
-
Monitor live signals (user feedback, safety flags, hallucination rates) and close the loop: bad production cases -> prioritized rater queue -> reward-model re-train.
-
Scale thoughtfully: use assisted raters (AI critics), active learning to prioritize examples, quotas to control annotation cost, and contract SLAs with label vendors.
(Foundational research and practical guides from OpenAI, Anthropic, and Hugging Face are useful starting points.)
1) Design: start with product outcomes, not metrics
Before collecting one label, define the behaviours you want to optimize. Good alignment is goal-directed.
Ask:
-
What product outcomes matter? (e.g., reduce support deflection, increase first-response correctness, avoid toxic responses.)
-
Which failure modes are critical? (privacy leaks, unsafe instructions, hallucinations that lead to monetary loss).
-
What is the operational definition of “good” for your product? (e.g., “answers that allow the user to complete task X without escalation, 95% of the time.”)
From outcomes, derive your feedback taxonomy — a short list of dimensions raters will evaluate. A typical taxonomy for conversational assistants includes:
-
Helpfulness / Usefulness (does this solve the user’s intent?)
-
Factual accuracy (contains verifiable facts?)
-
Safety / policy compliance (violence, hate, illicit requests)
-
Style / brand tone (concise, formal, friendly)
-
Request-handling correctness (e.g., followed user instructions, asked clarifying Qs)
Keep the taxonomy intentionally small (3–6 dimensions). Each extra axis multiplies rater complexity and cost.
2) Sampling strategy: what to label and why
You can’t label everything. Smart sampling is where most dollars are saved.
High-priority buckets:
-
Production failures: user complaints, high escalation rates, or messages flagged by heuristics. Prioritize these — they matter most to users.
-
Uncertain outputs: model confidence low or large divergence between candidate outputs. These are high-information for training reward models.
-
Edge-case prompts: rare but high-risk queries (legal/medical/financial). Label aggressively or route to safe fallback.
-
Drift-trigger samples: periodic random sampling to detect slow model drift.
Strategies:
-
Stratified sampling: allocate labeling budget across buckets (e.g., 40% production failure, 30% uncertain, 20% random, 10% edge).
-
Active learning: use a lightweight model to estimate which examples will change the reward model most, then surface those for labeling.
-
Hedging for fairness: ensure sampling covers user cohorts and languages to avoid biased reward models.
Whatever mix you pick, log the sampling rationale with metadata so you can explain why a data point entered the training set.
3) Rater workflows: build scalable, high-quality label operations
Your rater experience determines label quality. Good RLHF ops borrow from modern annotation best practices.
Task design principles
-
Keep tasks short and atomic: one decision or ranking per page.
-
Use pairwise comparisons where possible: humans are better at choosing between two options than scoring absolute quality. (OpenAI’s early RLHF used pairwise rankings effectively.)
-
Include simple, actionable instructions and examples (1–3 positive and negative). Avoid long legalese.
Comparison vs scalar labels
-
Pairwise ranking: Raters choose “A or B” — easier to get consistent reward signals.
-
Likert or scalar ratings: Useful for dimensions like “tone,” but need stronger calibration.
Rater tooling & UI
-
Show context and candidate outputs side-by-side. Include the prompt, any earlier turns, and relevant system instructions.
-
Include quick metadata toggles (safety flag, hallucination flag) and a free-text “why” field (short) for edge cases.
-
Implement keyboard shortcuts (1/2/3) and one-click “skip” for non-judgable items.
Rater training and calibration
-
Onboard with a 50–200 example training set and periodic calibration tests.
-
Track inter-rater agreement (Cohen’s kappa or Krippendorff’s alpha) and set thresholds. If agreement < target, run recalibration sessions.
-
Use gold-standard examples mixed into batches to detect rater drift and trigger retraining.
Ops: QA and throughput
-
Maintain rater SLAs: decisions per hour, agreement targets, average task time.
-
Use a “two-pass” policy for critical labels: primary rater + adjudicator. Use adjudication only on disagreement to save cost.
-
Keep rater groups small and specialized for complex domains (medical annotators separate from general web raters).
Scalable vendors vs in-house
-
Vendors (Scale, Appen, Surge, etc.) are great for scale but require strict QA funnels and contractual safeguards. Open-source tooling (Label Studio, Labelbox) + in-house QA gives more control.
4) Label quality: verification, aggregation, and balancing
Raw rater labels are noisy. You need pipelines that convert noisy judgments into usable training targets.
Aggregation patterns
-
Majority vote for categorical labels.
-
Borda count or Bradley–Terry models for pairwise rankings to derive a cardinal reward value. (Reward-model training benefits from relative preferences converted into likelihoods.)
-
Weighted aggregation using rater reliability scores — weight raters who historically agree with adjudicators more highly.
Rater reliability tracking
-
Give each rater a “reliability score” computed via gold items and adjudication outcomes. Use it both to weight labels and to detect problematic annotators.
Calibration
-
Periodically re-run a calibration set to rescale Likert scores across time or rater cohorts. For instance, what “4/5 helpful” means may drift; re-anchor scale with fresh gold items.
Label audits
-
Do monthly audits on a random sample of labels. Track error modes and publish an internal “label-health” dashboard to stakeholders.
5) Reward-model training & evaluation
Once you have preference data, the sequence is typically:
-
Train a reward model (RM) on pairwise preferences or scalar labels.
-
Use supervised fine-tuning (SFT) as a warm start to create a sensible policy.
-
Apply RL (PPO, DPO, or safer alternatives) to optimize the policy using the RM as the reward signal.
-
Evaluate with held-out preference sets, simulated users, and real-user A/B tests.
Practical tips
-
RM capacity: RMs can be smaller than the policy model, but must be robust across prompt distributions — validate on held-out production examples. Hugging Face resources and community recipes explain typical RM architectures.
-
Overfit risk: Reward models can be gamed — they may assign high scores to loophole outputs. Use diverse preference data, safety-specific labels, and adversarial examples to harden the RM.
-
Alternatives to PPO: DPO (Direct Preference Optimization) is an emerging alternative that avoids RL instability by directly optimizing for preferences; consider it for lower operational complexity. Wikipedia and recent literature discuss DPO and related methods.
Evaluation gating
Before any policy update reaches production, run:
-
Offline metrics: win-rate on held-out preference pairs, RM calibration, hallucination detector rates.
-
Safety checks: content-filter pass rates, trigger counts for banned categories.
-
Canary & A/B: route a small traffic share to the new model; compare user satisfaction and escalation rates.
6) CI for alignment: automate the loop
Treat RLHF like continuous delivery. Build CI pipelines that:
-
Pull new labeled data (from rater queue or production ingestion).
-
Re-train RM and SFT automatically on schedule or trigger (e.g., 10k new labels).
-
Run unit tests (gold-set accuracy), regression tests (no worse than baseline on critical slices), and safety checks.
-
If gates pass, launch a staged rollout: canary → 10% → 50% → 100%, with rollback triggers.
-
Log ablation experiments and associate model artifacts with data snapshots (data, code, hyperparams).
Infrastructure: Use reproducible training pipelines (MLflow, DVC, or ML orchestration with GitOps). Keep artifacts immutable (model hash + dataset hash) for auditability.
7) Production monitoring — the feedback loop back to raters
Once models serve users, monitoring is the engine that keeps alignment current.
Key signals to monitor
-
User-level feedback: thumbs up/down, explicit corrections, escalation to humans.
-
Model-side heuristics: hallucination detector hits, confidence scores, policy-tag counts.
-
Business KPIs: task completion rate, support deflection, conversion lift.
-
Token & cost anomalies: sudden increases in generated tokens per request.
Closed-loop pipeline
-
Flag production examples with failure signals.
-
Prioritize and triage (severity, frequency, customer tier).
-
Push prioritized examples into the rater queue for preference labeling or safety annotation.
-
Retrain RM and policy as required.
Automate prioritization using scoring rules (severity × frequency × customer value) and ensure high-severity items get expedited review.
8) Scaling with semi-automation & AI-assisted raters
At scale, full human labeling is expensive. Use assisted workflows:
-
Critic models: smaller evaluators (e.g., CriticGPT-style) pre-score outputs and surface disagreements to humans for faster adjudication. OpenAI reported that AI critics can speed up rater throughput and detect subtle issues.
-
Label prefill: provide raters with prefilled suggestions (e.g., likely ranking) they can accept or correct. This reduces time per item and increases throughput.
-
Active learning + batch selection: present raters with most informative examples rather than random ones.
Always keep a human-in-the-loop for final adjudication on safety or high-impact labels.
9) Cost engineering & resource planning
RLHF ops can be expensive — labels, compute for PPO, and SLO-driven production costs.
Cost levers
-
Label efficiency: prioritize pairwise ranking and active sampling to maximize information per label.
-
RM size & cadence: smaller RMs are cheaper to retrain; retrain cadence should match drift velocity.
-
PPO budgeting: run limited PPO epochs and rely on SFT + DPO where appropriate to reduce costly RL training.
-
Hybrid human/AI raters: use critic models to reduce human review load.
Model your expected annotation cost: estimated examples × labels per example × price per label; compare with value (reduced escalations, increased retention) to justify budget.
10) Governance, privacy, and vendor management
RLHF pipelines touch user content and potentially PII. Treat governance as non-negotiable.
-
Consent & disclosure: disclose if user content may be used for model improvement; provide opt-outs where legally required.
-
Data minimization: store only what you need for training and keep label metadata separate from raw user identifiers.
-
Vendor DPAs: if using external raters, ensure DPAs and security controls (managed access, limited download, watermarking).
-
Auditability: maintain immutable logs linking model versions to the datasets and rater snapshots used for training.
11) Human rater ethics & well-being
Labeling can expose contractors to disturbing content. Implement:
-
Rotation & mental health breaks, content warnings, and opt-out flows for sensitive categories.
-
Compensation fairness and clear task descriptions.
-
Escalation & debrief pipelines for raters who see harmful material.
This is both moral and practical — turnover and low quality follow from poor rater treatment.
12) Example production loop (concrete)
-
User asks a risky finance question → model answers and triggers hallucination detector.
-
Monitoring flags and places example in a “high-severity” bucket.
-
Arbiter prioritizes examples using severity × customer tier.
-
Rater workflow shows original prompt + 3 candidate replies; raters rank and annotate factual errors.
-
Aggregation creates preference label and safety tag.
-
CI pipeline ingests label, retrains RM, validates on gold sets, then runs safe PPO/DPO updates in a staging environment.
-
Canary deploy with 2% traffic; metrics monitored for 48 hours.
-
Full rollout if metrics show no regression; otherwise rollback and iterate.
13) Pitfalls to avoid
-
Collecting lots of low-signal labels. Prioritize data quality and informativeness.
-
No gold standard or adjudication policy. Without adjudication, labels drift and reward models degrade.
-
Skipping safety gating. It’s easy to optimize for “helpfulness” at the expense of safety if gating is weak.
-
Treating RLHF as one-off. It should be continuous — models and users drift.
14) Roadmap & checklist to start RLHF ops (first 90 days)
Week 1–2: Define taxonomy, sample production failure cases, build simple rater UI with a handful of gold examples.
Week 3–4: Stand up initial rater pool (in-house or vendor), collect 1k–5k pairwise labels, compute inter-rater agreement.
Week 5–8: Train initial reward model, run SFT / small DPO experiment, test offline metrics.
Week 9–12: Build CI gating, run a PPO (or controlled DPO) rollout in staging, implement monitoring & closed-loop queue from prod.
Month 4+: Invest in active learning, critic assistance, rater workforce scaling, and governance processes.
Final thoughts
RLHF ops is the discipline that turns human preferences into repeatable, auditable model behaviour. The heavy lifting is organizational and operational: building rater workflows, maintaining label quality, automating training & CI, and closing the loop from production back to raters. Do that well and you have a defensible, continuously improving alignment pipeline.